
Daily readiness is the practice of asking an athlete how they feel before training and using the answer to modulate the day’s load. It is one of the cheapest pieces of monitoring infrastructure in elite sport, and according to a substantial body of evidence published over the last three decades, also one of the most informative.
The story of how it became standard is, like the story of RIR, a lineage rather than a single discovery. It runs from the University of Queensland in 1995, through the Australian Institute of Sport, to a 2016 systematic review that surprised the field by showing that asking an athlete how they feel often outperforms measuring what their body is doing.
Hooper, 1995
The canonical reference is Sue Hooper and Laurel Mackinnon’s 1995 paper in Medicine & Science in Sports & Exercise, titled “Markers for monitoring overtraining and recovery.” Hooper, working at the University of Queensland’s Department of Human Movement Studies, monitored fourteen elite Australian swimmers across a six-month training season. The athletes filled in daily logs of subjective ratings — perceived exertion, sleep quality, fatigue, muscle soreness, stress, mood — alongside objective measures including resting and exercise heart rate, blood pressure, oxygen consumption, and a panel of blood markers covering enzymes and hormones.
Three of the fourteen swimmers became “stale” — the term then used for what would later be called overreaching or overtraining — based on performance deterioration and prolonged high fatigue. The interesting result was not that staleness happened, but what predicted it. Hooper’s regression analysis found that a battery of subjective well-being ratings accounted for 76% of the variance in staleness scores. Adding the late-season stress ratings and resting plasma catecholamines pushed it to 85%. Most of the predictive signal was in the questions, not the bloodwork.
The questionnaire that came out of this — typically four items (sleep, fatigue, stress, muscle soreness) on a 1-7 Likert scale, summed for a single readiness number — became known as the Hooper Index or the Hooper-Mackinnon questionnaire. It is still in use thirty years later, often unchanged. Its survival is partly a function of design: four questions, takes thirty seconds, requires no equipment, scales from one athlete to a squad to an institute.
The AIS tradition
Hooper’s work emerged from a wider Australian sports science context that became the dominant institutional source for monitoring research over the next two decades. The Australian Institute of Sport, founded in 1981, built its programme around the integration of physiological testing and applied training science, and a generation of practitioners and researchers — Andrew McLean, Paul Gastin, David Pyne, Shona Halson, and others — produced the bulk of the literature on how subjective monitoring should actually be implemented in elite sport.
The Gastin-led work in elite Australian football (the 2013 paper “Perceptions of wellness to monitor adaptive responses to training and competition in elite Australian football” in the Journal of Strength and Conditioning Research) is one of the cleaner demonstrations that simple wellness ratings, captured daily, track the rigours of professional competition closely enough to be useful for decision-making. The pattern was consistent across studies: Australian researchers, working with Australian elite-sport institutions, showing repeatedly that brief daily wellness questionnaires had practical utility.
This matters historically because it created the institutional context in which the next paper became possible.
Saw, Main and Gastin, 2016
In March 2016, Anna Saw, Luana Main and Paul Gastin published a systematic review in the British Journal of Sports Medicine with a title that telegraphs its conclusion: “Monitoring the athlete training response: subjective self-reported measures trump commonly used objective measures: a systematic review.”
The review covered 56 studies and compared the responsiveness of subjective measures (mood, perceived stress and recovery, wellness questionnaires) against objective measures taken at rest (heart rate, blood markers, cortisol) and during exercise (oxygen consumption, exercise heart rate). The result was that subjective measures responded earlier, more sensitively, and more consistently to changes in training load than the objective measures they were compared against. Wellness ratings dropped before cortisol shifted; mood deteriorated before heart rate variability changed; perceived recovery tracked load accumulation more reliably than blood markers.
The finding was counter-intuitive in the field. The default assumption in sports science had been that objective measurements were inherently more reliable than self-report, and that subjective tools were a fallback when laboratory access was limited. Saw, Main and Gastin’s review argued the opposite: that self-report was not just a convenient proxy for the “real” physiology, but in many contexts the more sensitive instrument.
The review did not claim subjective measures were universally superior. It claimed they were superior on the specific question of detecting acute and chronic training response in athletes, where the relevant signal is the integrated effect of load on the whole organism — exactly the kind of multi-dimensional change that subjective experience appears to integrate well.
The parallel: Buchheit and HRV
Running alongside the subjective-monitoring tradition is a parallel objective one, focused on heart rate variability. The dominant figure in the modern HRV-for-readiness literature is Martin Buchheit, formerly of Aspetar and Paris Saint-Germain, whose work since the early 2010s has built much of the methodological framework for using HRV as a daily training-status indicator.
The Plews-Laursen-Buchheit research line, published mostly in Sports Medicine and the International Journal of Sports Physiology and Performance between 2012 and 2017, established several practical points: HRV is best used as a moving average rather than a single daily measurement, the most informative metric is RMSSD (root mean square of successive R-R interval differences), and individual baselines matter more than absolute values. The work made HRV-based readiness monitoring viable for applied sport, in part by addressing the noise and compliance problems that had limited earlier adoption.
The HRV story and the subjective-monitoring story are not in opposition. The current consensus, supported by the Saw review and by Buchheit’s own writing, is that the two methods capture different things — subjective measures integrate psychological, social, and physical load; HRV captures autonomic-nervous-system status — and the strongest monitoring frameworks combine them.
Where daily readiness breaks down
The known limitations of subjective wellness monitoring are well-characterised in the literature.
Response bias is the first problem. Athletes learn what answers their coach wants to see. If a low readiness rating produces a reduction in load, the rational athlete who wants to do more will rate higher; the rational athlete who wants a rest day will rate lower. The questionnaire’s accuracy depends on a level of trust between athlete and coach that doesn’t always exist.
Fatigue itself reduces response quality. The athlete most in need of an accurate reading is the athlete least likely to give one, because chronic fatigue compresses the perceived range of well-being. People who are running on empty often rate themselves as moderately tired rather than very tired, because the very-tired baseline has shifted.
The four-item Hooper Index is small. It captures only the dimensions Hooper’s original swimmers happened to log. Some research groups have proposed extensions (the AIS uses a five-item version with an additional appetite or motivation question; some teams use up to ten items); others argue that adding items reduces compliance more than it improves signal. The right number of items for a daily readiness questionnaire is not settled.
And the link between questionnaire scores and what the platform should do about them is not fully specified. A drop of one point on a 7-point sleep rating means something. What it means for tomorrow’s training prescription depends on the sport, the athlete’s training age, the phase of the season, and dozens of other variables that the questionnaire itself does not capture.
What the literature supports unambiguously is that asking is better than not asking. The signal is real, the cost is negligible, the implementation is straightforward, and the alternative — relying on objective markers alone — has been repeatedly shown to be slower and less sensitive.
In Afitpilot
Daily readiness sits inside Afitpilot’s adaptive architecture as the pre-session input. Session RPE and RIR are post-hoc measurements — they tell the platform what happened in a session that has already been completed. Daily readiness is the only signal in the loop that arrives before the session.
The input format is the AIS five-item variant of the Hooper questionnaire — sleep, soreness, fatigue, mood, stress — summed on a 5–35 scale. This is a step beyond Hooper’s original four items, picking up the mood extension the AIS added in the years after the 1995 paper. It remains compact enough to take thirty seconds and scale cleanly across users without requiring instrumentation.
Today, the platform captures the reading and surfaces it: the athlete sees a live Hooper gauge with a severity tier, and coaches see the aggregate via the readiness telemetry layer. The load-modulation loop — using a low score to reduce intensity, cap volume, or substitute a recovery-oriented session in place of a high-stress one — is the design intent rather than the current behaviour. The adaptation hook is not yet wired to the prescription engine, and readiness is, for now, an isolated service alongside the other inputs rather than fused with them.
The design will have to account for the limitations the literature flags once the modulation loop is live. Response bias is the obvious one: as soon as a low score reduces load, athletes have an incentive to rate strategically. The intended mitigations are transparency about what a given score will do to the prescription, and triangulation against the platform's other signals — recent training load, recent session RPE, and sleep duration where available — none of which are currently fused with readiness but all of which are captured elsewhere in the system. The five-item set is a starting point, not a fixed structure; the right number and content of items will likely shift as the platform's user base broadens beyond the early hybrid-athlete cohort.
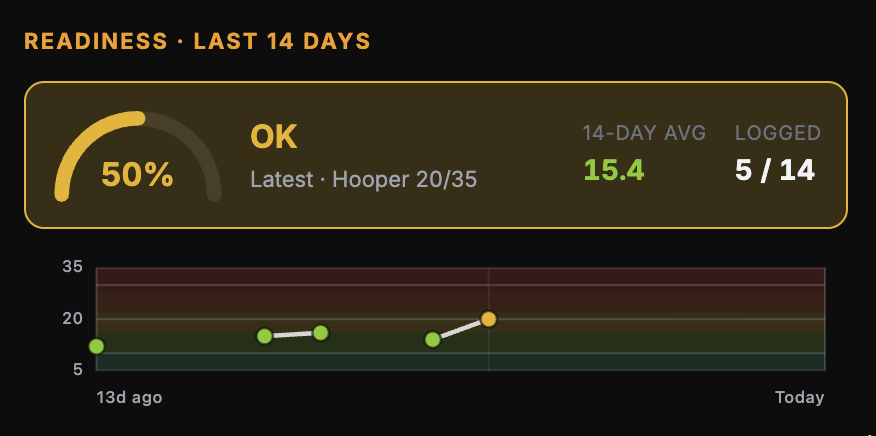
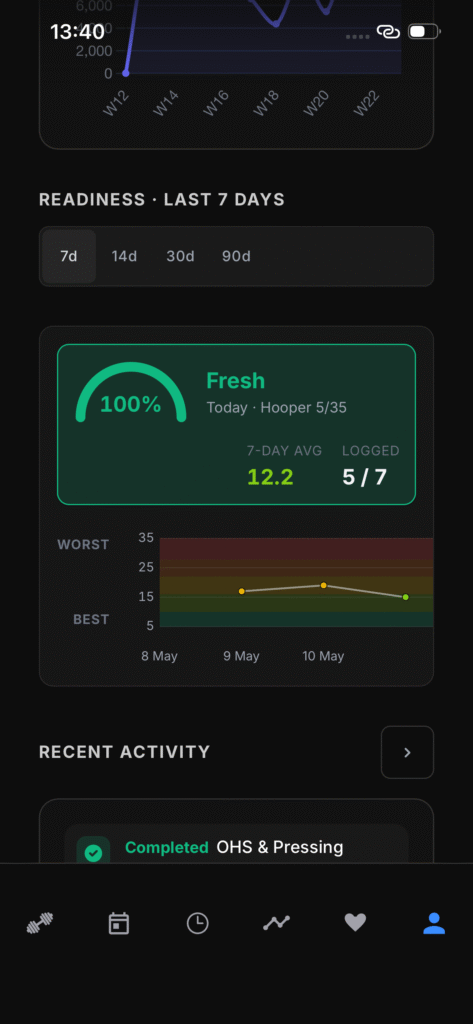
Asking how the athlete feels is a low-resolution measurement of a high-dimensional state. It is also, on the available evidence, the single highest-utility piece of pre-session information any training platform can collect.
I wrote separately about Gunnar Borg and reps in reserve, the two other measurement traditions that sit alongside readiness in the platform's input layer.
Leave a Reply
You must be logged in to post a comment.