
RIR — reps in reserve — is the strength-training cousin of Borg’s perceived exertion scale, applied per set rather than per session. Instead of asking “how hard was that?” on a generic scale, RIR asks the more specific “how many more reps could you have done before failure?” A set taken to true muscular failure is 0 RIR. A set with two reps left in the tank is 2 RIR.
Unlike the other measurement instruments in this series, RIR has no single inventor. It came out of a sequence of contributions across the gap between competitive strength training and academic exercise science — a coach in 2008, a research group in 2012, another research group in 2016. The fact that the practitioner’s version came first is part of why the lineage is worth telling. RIR is one of the cleanest examples of a coaching idea that the academic literature spent close to a decade catching up to.
Tuchscherer, 2008
The first formal use of RIR as a programming variable was in The Reactive Training Systems Manual, published in 2008 by the American powerlifter and coach Mike Tuchscherer [1]. RTS was a self-published methodology document for competitive powerlifters, sold through Tuchscherer’s own website. Its central innovation was using RPE-with-RIR-anchors as the primary tool for prescribing daily training intensity — a system Tuchscherer called autoregulation.
The Tuchscherer scale ran from 4 (“recovery”) to 10 (“maximal”), with the top three points anchored explicitly in RIR terms: RPE 10 = 0 reps left, RPE 9 = 1 rep left, RPE 8 = 2-3 reps left. A coach prescribing “5×3 @ RPE 8” was telling the athlete to do five sets of three repetitions, choosing a load on each set that left them with two or three reps in the tank. The load itself was self-selected; what was prescribed was the relationship between load and effort.
RTS was a working coaching system, not peer-reviewed research. Tuchscherer’s framework spread through the powerlifting community via online forums, training logs, and word of mouth. By the early 2010s, RPE-with-RIR-anchors was standard vocabulary in elite powerlifting — years before any of it appeared in a journal.
Hackett, 2012
The first peer-reviewed work on RIR-style estimation came from a research group at the University of Sydney, led by Daniel Hackett. Their 2012 paper in the Journal of Sports Sciences, titled “A novel scale to assess resistance-exercise effort,” introduced the Estimated Repetitions to Failure (ERF) scale, an 11-point scale ranging from 0 (failure reached) to 10+ (10 or more repetitions still possible) [2].
The Hackett team’s contribution was empirical: they validated that experienced bodybuilders could estimate reps-to-failure with reasonable accuracy. Their results also exposed the most important limitation of the method, which has shaped every subsequent paper: estimation accuracy is high when subjects are close to failure (within 0-3 reps) and degrades sharply when they are far from it. Asking a trained lifter “how many reps did you have left?” after a 3-RIR set produces tight, consistent answers. Asking the same question after a 7-RIR set produces noise.
Hackett’s group was working independently of Tuchscherer. The ERF scale and the RTS scale converged on the same idea from different directions — practitioner intuition on one side, controlled experimentation on the other.
Zourdos, 2016
The version of RIR that most strength coaches use today comes from a 2016 paper in the Journal of Strength and Conditioning Research by Mike Zourdos and colleagues at Florida Atlantic University, titled “Novel resistance training-specific rating of perceived exertion scale measuring repetitions in reserve” [3].
The Zourdos scale is a 1-10 scale that integrates RPE and RIR into a single instrument. The top six points (5-10) are anchored in RIR — RPE 10 = 0 RIR, RPE 9 = 1 RIR, RPE 8 = 2 RIR, RPE 7 = 3 RIR, RPE 5-6 = 4-6 RIR. The lower points (1-4) are anchored in generic perceived effort, because Hackett’s earlier work had shown that reps-to-failure estimation breaks down at distances greater than 3-4 reps from failure. The scale handles its own uncertainty by collapsing the unreliable range into a single bin.
Zourdos’s paper validated the scale empirically against barbell velocity in 29 squatters, and demonstrated that experienced lifters produce significantly more accurate ratings than novices — a finding with practical implications for how the scale should be deployed in coaching. The companion paper by Eric Helms and colleagues, published the same year in Strength and Conditioning Journal, walked through the practical applications of the scale in programming [4].
The Zourdos paper acknowledged Tuchscherer’s prior work explicitly. The Helms paper notes: “although Zourdos et al. have introduced an RIR-based scale into the scientific literature, a scale of this type was originally created in The Reactive Training Systems Manual in 2008 to be used in powerlifting-type training.” That citation is the cleanest formal acknowledgement in the academic literature that the practitioner-developed system came first.
Where RIR breaks down
The known limitations of the method are well-established in the literature and worth understanding before relying on RIR-based programming.
Accuracy degrades with distance from failure. Lifters can reliably distinguish 0 RIR from 2 RIR. They cannot reliably distinguish 6 RIR from 8 RIR. This is true for novices and experienced lifters alike, though experienced lifters have less noise across the whole range.
Accuracy degrades with rep count. A 2024 scoping review noted that RPE-RIR ratings are systematically less accurate on sets with more repetitions, which limits the method’s usefulness at lower percentages of 1RM [5]. A set of 12 with 3 RIR is harder to rate accurately than a set of 5 with 3 RIR.
Self-rating is subject to motivation and context. Trainees underestimate RIR when fatigued, overestimate when fresh, and are influenced by external pressure (a coach watching, a peer next to them). The scale assumes honest self-report and pays for that assumption when honesty isn’t there.
Inter-individual differences are real. Two lifters at the same physiological proximity to failure may rate the set differently, particularly in the 2-5 RIR range where neither failure nor abundant reserve is the obvious anchor. This limits the scale’s use as a between-subjects normalisation tool.
None of these limitations make RIR unusable. They make it a practitioner’s tool, best applied close to failure, by experienced trainees, with cross-checks against other variables (load, velocity, bar speed). The method works because it’s the best available estimate of a quantity that matters — proximity to failure as the primary driver of strength and hypertrophy adaptation — not because it’s precise.
In Afitpilot
RIR sits inside Afitpilot’s training-load thinking as the per-set complement to session RPE. Borg’s CR10 scale and Foster’s session-RPE-times-duration framework give a useful currency for endurance and conditioning work, where the load is roughly continuous over the session and a single rating captures it well. They handle resistance training less cleanly. A heavy strength session is a sequence of short, high-effort sets separated by rest; a single post-session rating averages out information that the per-set ratings preserve.
The platform captures RIR optionally on every set, on a 0–10 chip menu next to reps and weight, and never blocks a save if it’s left blank. Where RIR is present on a set, the server uses the Zourdos relationship — RPE = 10 − RIR — to derive a per-set RPE if one wasn’t entered explicitly, and feeds the result into the session’s e1RM estimate. That’s the single downstream consumer today: RIR is how the platform converts what was lifted into an inferred strength capacity. It is not yet a separate currency from session RPE in the load model.
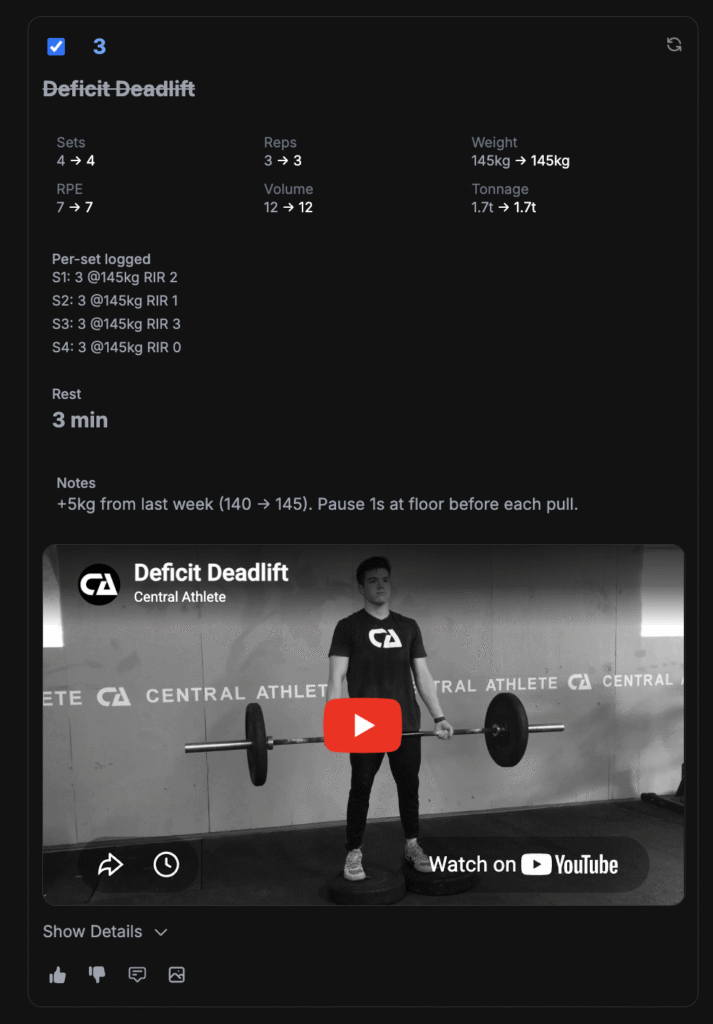
What the post above describes as the right design — weighting recent-to-failure sets more heavily, treating high-RIR ratings as low-resolution, and triangulating against load and (eventually) bar velocity — is design intent, not current behaviour. None of that logic is wired up. The platform also doesn’t currently capture velocity, which puts the triangulation work behind a hardware-or-input prerequisite that hasn’t been solved. The e1RM consumer is the floor; the load-model integration is the ceiling, and the gap is the roadmap.
The honest summary: RIR is captured, the Zourdos formula is implemented, and the data feeds the strength-capacity estimate. The richer use of RIR that the literature points toward — per-set load weighting, stimulus-vs-capacity tracking, accuracy-aware aggregation — is what the platform is being designed to grow into, not what it does today.
I wrote separately about Gunnar Borg and A.V. Hill, whose measurement work made the rest of this possible.
References
[1] Tuchscherer, M. (2008). The Reactive Training Systems Manual. Self-published.
[2] Hackett, D.A., Johnson, N.A., Halaki, M., & Chow, C.M. (2012). A novel scale to assess resistance-exercise effort. Journal of Sports Sciences, 30(13), 1405–1413.
[3] Zourdos, M.C., Klemp, A., Dolan, C., Quiles, J.M., Schau, K.A., Jo, E., Helms, E., Esgro, B., Duncan, S., Garcia Merino, S., & Blanco, R. (2016). Novel resistance training-specific rating of perceived exertion scale measuring repetitions in reserve. Journal of Strength and Conditioning Research, 30(1), 267–275.
[4] Helms, E.R., Cronin, J., Storey, A., & Zourdos, M.C. (2016). Application of the repetitions in reserve-based rating of perceived exertion scale for resistance training. Strength and Conditioning Journal, 38(4), 42–49.
[5] Bastos, V., Machado, S., & Teixeira, D.S. (2024). Feasibility and usefulness of repetitions-in-reserve scales for selecting exercise intensity: a scoping review. Perceptual and Motor Skills, 131(4), 1394–1418.
Leave a Reply
You must be logged in to post a comment.